
In 2026, building resilient n8n workflows requires a multi-layered approach to ensure transient issues like API timeouts or malformed data do not lead to silent failures or total system crashes.
Table of Contents
1. Node-Level Retry Settings
The first line of defense was the built-in retry mechanism found in settings of almost each node (e.g., HTTP Request or AI Agent).
- Enable Retry on Fail:Switch this to ON to automatically re-attempted the task after the failure.
- Configure Max Tries:Setting the number of attempts (typically 3–5) before node finally give up.
- Wait Time:Defined the delay (in seconds and milliseconds) between attempts. For external APIs, a 5-second delay was often recommended to permit services to recovered.
- Exponential Backoff:If supported or manually construct up via a loop, this increases the delay after each failed attempt to provide struggling servers much more breathing room.
2. Centralized Error Workflows
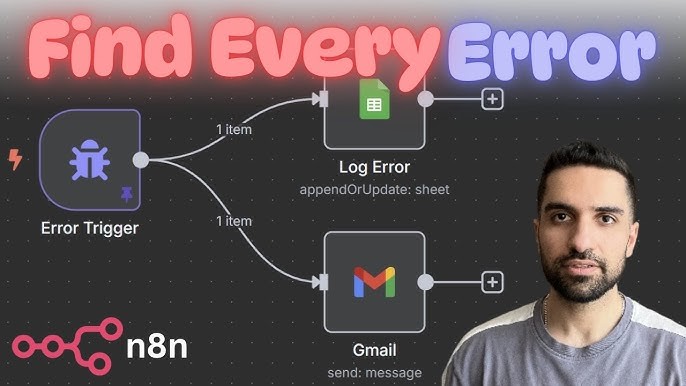
For comprehensive monitoring, develop the devoted “Error Handler” workflow that acts as mission control for complete instance.
- Error Trigger Node:Began this separate workflow with Error Trigger It captured specific details when some other workflow fails, included the workflow name, node name, and exact error messaging.
- Link Workflows:In the Settings of the main workflows, selecting the Error Handler from the “Error Workflow” dropdown.
Actions: Using this workflow to send out instant notifications (Slack, Discord, or Email) or log errors into the database for longer-term tracking.
3. Graceful Failure Management
Instead of let the single “bad apple” stopped the full batch, using routing to isolated failures.
- Continue On Fail:Changed a node’s “On Error” setting to “Continue (using error output)”. This develop the red output branch on node.
- Separate Lanes:Route successful items down the failed items and standard path down the error path to custom logic like logging to the “Manual Review” sheet or try out the secondary “Fallback” service.
4. Advanced Resilience Strategies
- Stop and Error Node:Using this to intentionally triggered the failure when business logic conditions were not met (e.g., missing critical data), certains the global error workflow was alerted.
- Polling Loops:For longer term-running tasks, usage the loop with Wait and IF nodes to periodically check in API status until completion, rather than the wait indefinitely.
- Fallback Logic:Design your workflow to switch to a “Plan B,” such as a secondary AI model or backup SMS provider, if the primary one fails after retries.
5. Best Practices for 2026
- Validate Data Early:Use IF nodes at the beginning of workflows to check to missing or malform fields before they reached critical external nodes.
- Modular Design:Break large monolithic workflows into smaller sub-workflows using the Execute Workflow node to isolate risky operations.
- Monitoring Executions:Regularly check the Executions Log to identify recurring failure patterns and adjust retry logic accordingly.

6. Node-Level Retries (First Line of Defense)
For transient errors like network hiccups or temporary API outages, the built-in “Retry on Fail” featuring is the simple solution.
- How to set up:
- Choose the particular node you anticipated may failed (e.g., an HTTP Requestnode).
- In node’s settings panel, find and enabled the Retry on Fail
- Configured the Max Tries(e.g., 3-5 attempts) and a Wait Time (delay between retries).
- For much more advanced handling, you could implemented the exponential backoff strategy usage the custom loop with Set, If, and Waitnodes to increased delay between attempts.
7. Continue on Error (Isolating Failures)
This process certains that the single failed item in the batch did not stop the full workflow, permit the rest of the stuff to process out successfully.
- How to set up:
- In the settings of the potentially failing node, changing the error handling from “Stop Workflow” to Continue (usage Error Output).
- This created the separate, red output path on node for products that failed.